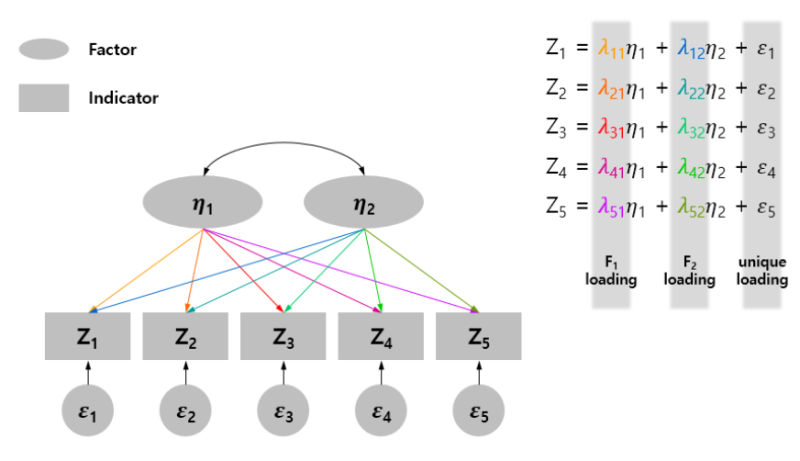
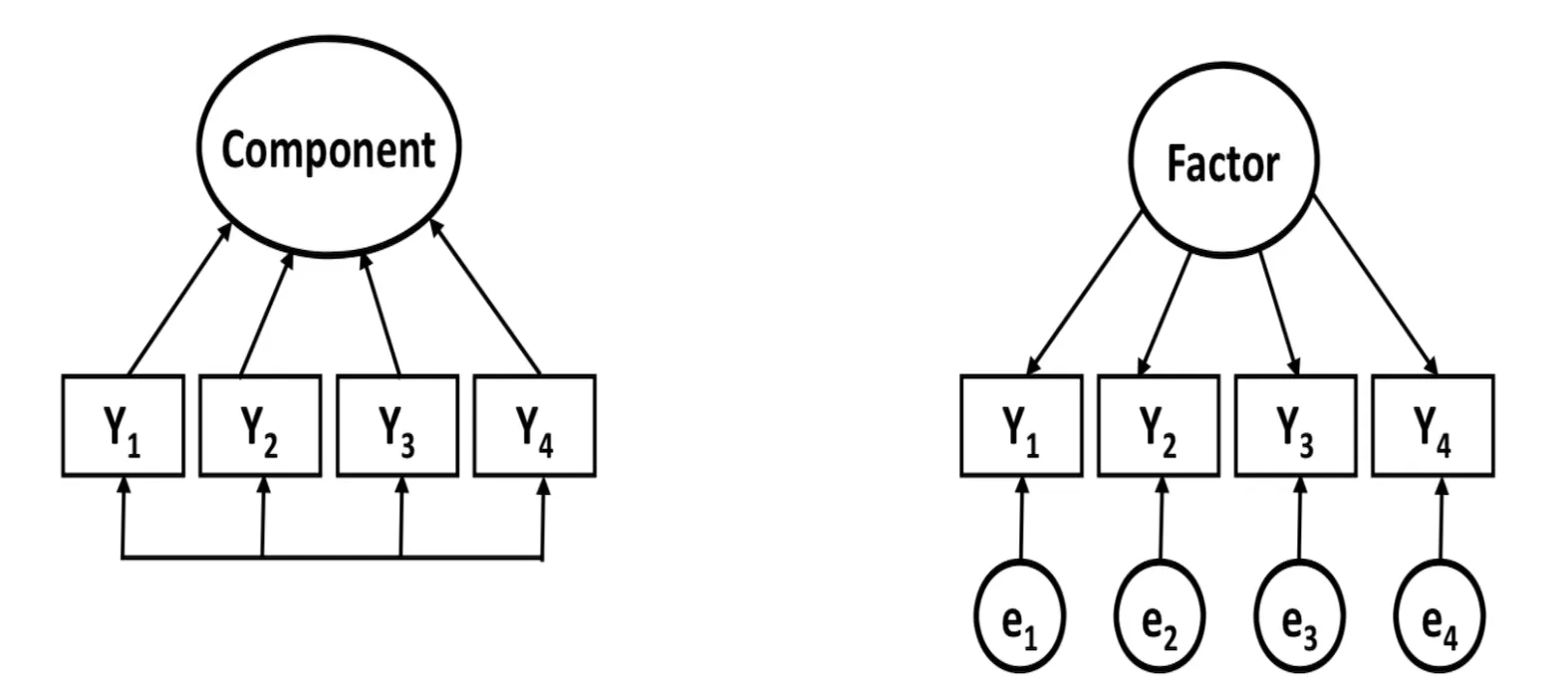
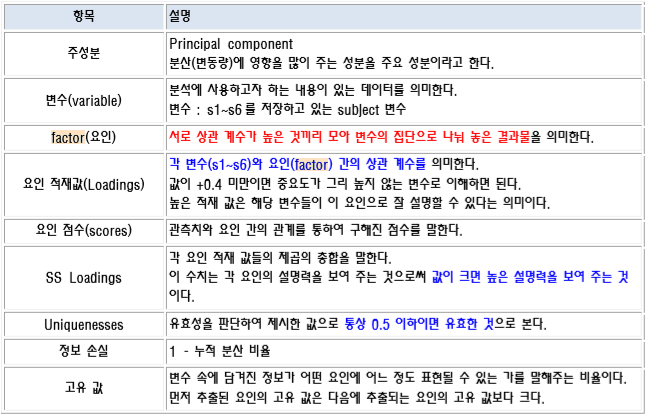
#R#원인 분석#상관 관계 분석 요인 분석의 종류 요인 분석이란 간단히 말하면 변수의 개수를 축소하는 과정입니다. 복수 변수 간 관계를 분석하고 관계가 강한 변수들을 묶은 통계 방법입니다. 요인 분석은 탐색적 요인 분석과 확인적 요인 분석에 나누어집니다. 탐색적 요인 분석은 분석 시에 어떤 변수들을 묶는지를 전제로 하지 않고 분석하는 방법이요, 확인적 요인 분석은 사전에 얽매이는 것이 기대되는 항목끼리 묶는지 조사하는 방법입니다. 탐색적 요인 분석을 통하여 먼저 변수를 군집화하고 적절치 못한 변수를 제외하고는 확증적 요인 분석을 통하여 군집화가 적절한지 확인하는 것입니다.깊이 들어가면 한도 끝도 없는데..일단 사양하겠습니다. 여기에서는 확증적 요인을 분석합니다. 요인 분석의 목적 1)변수의 축소:전술대로, 변수를 축소합니다. 변수가 너무 다중 공선성 문제 등에 의한 적절한 추정이 어려운 경우가 있어 때는 변수를 축소하는 과정도 필요합니다. 유난히 설문의 경우, 질문 수가 많지만 한가지 내용을 여러개의 질문 항목에서 듣는 것이 많습니다. 그런 경우, 요인 분석을 통하여 변수 개수를 줄여야 합니다.2)툴의 타당성 검증:설문서를 예로 들면 한가지 내용의 여러 질문을 작성했을 때, 그것이 같은 요인으로 맺어져야 같은 내용에 대해서 질문했다고 볼 수 있습니다. 3)불필요한 변수 제거, 사용하는 자료:스마트 폰 사용에 대한 만족도(임의로 작성했습니다)다음과 같이 7개의 변수는 총 2가지 요인으로 분류된다고 판단되고 이를 검증합니다. 또한 변수 값은 일정하게 표준화되고 있을 필요가 있습니다. 본고에서는 내가 임의로 데이터를 작성했고, 표준화 작업은 특히 거치지 않았습니다.

요인 변수명 변수 설명 척도 제품 성능 v1 처리 속도 모두 5점 척도입니다. 5점 매우만족4점 만족3점 보통2점 불만족1점 매우불만족v2 호환성v3 내구성v4 가성비비비제품 친밀도v5브랜드v6익숙v7적응성

데이터 <-readxl:: read_excel(“D: /LSW/RDirectory/phone_satfaction.xlsx”) 뷰(데이터)
상기 데이터 프레임 형식의 데이터이며 샘플은 50개입니다.탐색적 분석이라면 주성분 분석 방법이나 고유값을 활용해서 요인 수를 조사하지 않으면 여기서는 이미 요인을 정해 검증할 수 없기 때문에 통과하고 바로 요인 분석으로 넘어갑니다. 요인분석> result <-factanal(data, factor=2,rotation=”varimax”) # 요인을 두 가지로 지정하였으므로 factor=2, 요인회전법은 varimax회전법 사용> result

상기 데이터 프레임 형식의 데이터이며 샘플은 50개입니다.탐색적 분석이라면 주성분 분석 방법이나 고유값을 활용해서 요인 수를 조사하지 않으면 여기서는 이미 요인을 정해 검증할 수 없기 때문에 통과하고 바로 요인 분석으로 넘어갑니다. 요인분석> result <-factanal(data, factor=2,rotation=”varimax”) # 요인을 두 가지로 지정하였으므로 factor=2, 요인회전법은 varimax회전법 사용> result

색깔이 진할수록 빈도가 많은 부분입니다.피어슨 상관 계수(r)는-1<=r<=1의 값을 가진 정규이면 플러스 상관 관계, 마이너스이면 부의 상관 관계입니다.즉, 1은 완벽한 플러스 관계-1은 완벽한 부의 관계입니다. 어느 것이 1만 늘면 똑같이 1만 늘어날지 감소하는 것입니다. 실생활에서 상관 계수의 절대 값이 1의 경우는 거의 없습니다. 보통 그 사이의 값을 갖고 있지만, 일반적으로 절대 값이 0.2미만이면 상관 관계 없이 0.2~0.4이면 약한 상관 관계 0.4~0.7다면 다소 높은 상관 관계 0.7~0.9라면 높은 상관 관계 0.9이상이면 매우 높은 상관 관계라고 생각합니다.그래서 제품의 성능과 제품의 친밀도와 상관 관계가 어느 정도 있어~라고 해석됩니다. (물론. 실제와 다른 경우가 있습니다. 제가 임의로 만든 데이터 때문입니다.)